현대 로드밸런싱과 프록시에 대한 소개
최근, 현대 네트워크 부하분산(load balancing)/프록시에 대한 교육 자료가 부족하다는 사실을 알게 됐다. 어떻게 이럴 수가 있나? 로드밸런싱은 신뢰할 수 있는 분산 시스템의 핵심 개념 중 하나인데 말이다. 양질의 자료가 있어야 하는 것 아닌가? 그러나 검색해도 거의 없었다. 로드밸런싱/프록시 서버에 대한 위키피디아 문서는 일부 개념의 개요만을 포함할 뿐 주제에 대한 유동적인 처리법, 특히나 현대 마이크로서비스 아키텍처에 적용돠는 것은 없었다. 구글링 결과는 유행어만 많지 세부 정보는 적은 벤더 페이지가 주로 나올 뿐이다.
이 게시글에서는 현대 네트워크 로드밸런싱/프록시를 가볍게 소개해 다뤄 정보 부족을 조금 해소해보고자 한다. 이는 책 한 권이 될 수 있는 방대한 주제인데, 이를 블로그 길이 정도로 유지하기 위해 복잡한 주제를 간단한 개요로 추출하고자 노력했다; 개별 주제에 대한 더 상세한 정보는 흥미와 피드백에 따라 후속 게시물에서 다룰 것이다.
이 글을 쓴 이유와 함께 - 자 시작해보자!
네트워크 로드밸런싱과 프록시란 무엇인가?
위키피디아는 로드밸런싱을 다음과 같이 정의한다:
컴퓨팅에서, 로드밸런싱은 작업물을 여러 컴퓨팅 자원(컴퓨터, 컴퓨터 클러스터, 네트워크 링크, 중앙 처리 장치, 디스크 드라이브 등)에 분산하는 일을 개선한다. 로드 밸런싱의 목적은 자원 활용률을 최적화하고, 처리량을 극대화하고, 응답시간을 최소화하고, 개별 자원의 과부하를 방지하는 것이다. 구성요소를 단일로 쓰는 대신 여럿으로 로드밸런싱하면 중복성이 생겨 신뢰성과 가용성을 증가시킬 수 있다. 로드밸런싱은 일반적으로 전용 SW나 HW를 포함한다.(멀티레이어 스위치, DNS서버 프로세스 등)
상술한 정의는 네트워크 뿐 아니라 컴퓨팅의 모든 측면에 적용된다. OS는 로드밸런싱을 사용해 물리 프로세서에 태스크를 스케쥴링하고, 컨테이너 오케스트레이터쿠버네티스는 로드밸런싱을 사용해 클러스터에 태스크를 스케쥴링하며, 네트워크 로드밸런서는 네트워크 태스크를 가용한 백엔드에 스케쥴링한다. 이 글은 네트워크 로드밸런싱에 대해서만 다룰 것이다.

그림 1: 네트워크 로드 밸런싱 개요
그림1은 네트워크 로드밸런싱의 고수준 개요를 보여준다. 일부 클라이언트가 일부 백엔드에 자원을 요청하고 있다. 로드밸런서는 클라이언트와 백엔드 사이에 위치해 고수준에서 몇가지 핵심적인 작업을 수행한다:
서비스 검색: 시스템에서 사용할 수 있는 백엔드는 무엇인가? 그들의 주소는 무엇인가? (즉, 로드밸런서가 그들과 어떻게 통신하는가?)헬스 체킹: 현재 건강해 요청을 받을 수 있는 백엔드들이 어떻게 되는가?부하 분산: 개별 요청을 건강한 백엔드에 분산시킬 때 어떤 알고리즘을 사용할 것인가?
분산 시스템에서 로드 밸런싱을 적절하게 사용하면 몇 가지 이점을 얻을 수 있다:
명명 추상화: 모든 클라이언트가 모든 백엔드의 이름을 알 필요가 없다.(서비스 검색) 클라이언트는 사전에 정의한 메커니즘에 따라 로드밸런서를 알 수 있으며, 백엔드 이름 해석은 로드밸런서가 처리할 것이다. 사전에 정의한 메커니즘은 내장 라이브러리와 well-known DNS/IP/port 위치를 포함하며, 추가적인 세부사항은 후술할 것이다.내결함성: 헬스 체킹과 다양한 알고리즘 기법을 통해, 로드밸런서는 불량하거나 과부화된 백엔드를 효과적으로 우회할 수 있다. 즉, 문제 백엔드를 긴급하게 조치하지 않아도 당장 문제가 생기지는 않는다는 뜻이다.비용/성능 이점: 분산 시스템 네트워크는 거의 균일하지 않다. 시스템은 여러 네트워크 존(zone)과 리젼에 걸쳐 있을 가능성이 높다. 일반적으로 동일 존 내 네트워크는 상대적으로 부하가 적고, 존 간에는 부하가 높다. (부하의 기준은 라우터 간 대역폭 대비 NIC이 사용 가능한 대역폭량이다.) 지능적인 부하분산은 요청 트래픽을 최대한 존 내로 유지함으로써 성능을 늘리고 지연을 줄여 전체적인 성능 비용을 줄인다. (존 간 필요한 대역폭 및 회선량 감소)
로드밸런서 vs 프록시
네트워크 로드밸런서를 얘기할 때, 로드밸런서와 프록시란 용어는 업계 내에서 대강 동의어로 사용된다. 이 게시글도 이 용어들을 일반적으로 동일한 것으로 취급할 것이다. (엄밀히는 모든 프록시가 로드밸런서인 건 아니지만, 대부분의 프록시는 기본적으로 부하분산 기능을 수행한다.)
혹자는 추가적으로 로드밸런싱이 임베디드 클라이언트 라이브러리의 일부로 수행될 때, 로드밸런서가 정말 프록시인 건 아니라고 주장할 수도 있다. 그러나, 그러한 구분은 이미 혼란스러운 주제에 불필요한 복잡성을 더할 뿐이다. 로드밸런서 구조의 유형은 아래에 자세히 설명하겠지만, 이 게시물은 임베디드 로드밸런서 구조를 프록시의 특별 사례로 취급할 것이다. 해당 구조에서 프록시 용도로 사용하는 내장 라이브러리가 외부 로드밸런서와 동일한 추상화를 제공하는 것이기 때문이다.
L4 (커넥션/세션) 로드밸런싱
오늘날 업계 전반에서 로드밸런싱을 논의할 떄, 보통 해결책은 두 가지, L4/L7으로 분류된다. 이들 카테고리는 OSI 모델의 4/7레이어를 지칭한다. L7 로드 밸런싱을 다룰 때 얘기하겠지만, 개인적으로는 이런 용어가 마음에 들지 않는다. OSI 모델은 로드밸런싱 솔루션의 제대로 된 근사가 아니기 때문이다. L4 로드밸런서가 TCP/UDP 같은 전통적인 4레이어 프로토콜을 포함하긴 하지만, 다른 여러 계층 프로토콜의 비트/조각들도 포함한다. 즉, L4 TCP 로드밸런서가 TLS 종료(termination)도 지원하면, L7 로드밸런서가 되는 것인가?
그림 2: TCP L4 termination 로드 밸런싱
그림2는 전통적인 L4 TCP 로드밸런서를 보여준다. 이 경우, 클라이언트는 TCP 커넥션을 로드밸런서와 맺는다. 로드밸런서는 커넥션을 종료하고,(SYN에 바로 응답하고) 백엔드를 선택해 새 TCP 커넥션을 만든다.(새 SYN을 보낸다) 그림의 세부적인 면은 신경쓰지 말라. 세부사항들은 L4 로드밸런싱 문단에서 다룰 것이다.
이 문단의 핵심은 L4 로드밸런서가 일반적으로 오직 L4 TCP/UDP 커넥션/세션 수준에서만 동작한다는 사실이다. 그러므로 로드밸런서는 패킷을 대강 섞되, 동일한 세션의 패킷은 동일한 백엔드에 향하도록 하는 것이다. L4 로드밸런서는 뒤섞는 패킷의 어플리케이션 세부사항은 알지 못한다. 데이터는 HTTP, Redis, MongoDB 등일 수 있다.
L7(어플리케이션) 로드밸런싱
L4 로드 밸런싱은 간단해 여전히 널리 사용되고 있다. 그렇다면 L7 로드 밸런싱에 비한 L4 로드 밸런싱의 단점은 무엇일까? 다음 L4 사례를 살펴보자:
gRPC/HTTP2클라이언트 둘이 백엔드와 통신을 희망해 L4 로드밸런서를 통해 연결했다.- L4 로드밸런서는 incoming TCP 연결마다 단일 outgoing TCP 연결을 만들기 때문에, 최종적으로 두개의 incoming/outgoing 연결이 만들어진다.
- 그런데, 클라이언트 A는 요청을 분당 1회 보내는 반면,(RPM) 클라이언트 B는 초당 50번(RPS) 보낸다.
여기서, 클라이언트 B를 다루는 백엔드는 A를 다루는 백엔드보다 대강 3000배의 부하를 처리한다! 이는 큰 문제로 일반적으로 부하분산을 무의미하게 만든다. 또한 이 문제는 멀티플렉싱[^multiplexing], kept-alive[^kept-alive] 프로토콜이면 어디서든 발생할 수 있다는 사실을 유념하라. 모든 현대 프로토콜은 효율성 때문에 멀티플렉싱/kept-alive를 채택하고 있으므로, L4 로드밸런서의 부하 불균형 문제는 점점 뚜렷해지고 있다. 이 문제는 L7 로드밸런서로 극복할 수 있다.
[^multiplexing]: 멀티플렉싱이란 병렬 어플리케이션 요청들을 단일 L4 커넥션으로 보내는 것을 의미한다.
[^kept-alive]: kept-alive는 활성화된 요청(active request)이 없을 때 커넥션을 끊지 않는 것을 의미한다
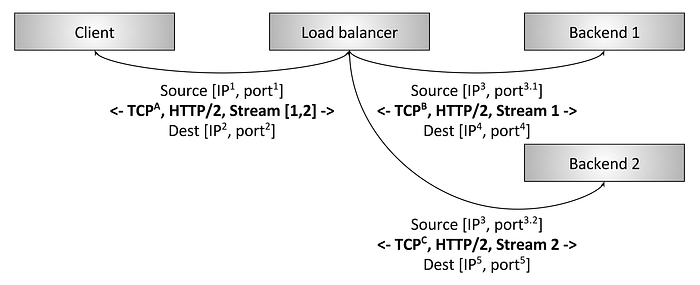
그림 3: HTTP/2 L7 termination 로드 밸런싱
그림3은 L7 HTTP/2 로드밸런서를 보여준다. 이 경우, 클라이언트는 로드밸런서로 단일 HTTP/2 TCP 커넥션을 만든다. 그러면 로드밸런서는 백엔드 커넥션을 두 개 만든다. 클라이언트가 두 HTTP/2 스트림을 로드밸런서에게 보내면, 스트림1은 백엔드1로 전송되고, 스트림2는 백엔드2로 전송된다. 따라서 요청부하가 크게 다른 멀티플렉싱 클라이언트도 여러 백엔드에 걸쳐 효율적으로 균형을 맞출 수 있을 것이다. 이것이 현대 프로토콜에서 L7 로드 밸런싱이 중요한 이유이다. (L7 로드 밸런싱은 어플리케이션 트래픽을 검사할 수 있는 능력이 있어 이에 대한 막대한 추가 이점도 있지만, 이에 대해서는 나중에 자세히 다룰 것이다.)
L7 로드밸런싱과 OSI 모델
L4 로드밸런싱 문단에서 상술했듯, OSI 모델로 로드밸런싱 기능을 설명하는 건 문제가 있다. 그 이유는 L7이, OSI 모델에서 설명하는 것만 따져도 그 자체로 로드 밸런싱 추상화의 여러 개별 계층을 포괄하기 떄문이다. 예를 들어, HTTP 트래픽은 다음 서브레이어들을 고려한다:
- 선택적인 TLS(Transport Layer Security, 전송 계층 보안). TLS가 어느 OSI 계층에 속해야할지 네트워크 종사자 간에 논쟁이 있었다는 사실에 주의하라. 이 논의를 위해 우리는 TLS L7을 고려할 것이다.
- 물리적 HTTP 프로토콜 (HTTP/1나 HTTP/2)
- 논리적 HTTP 프로토콜 (헤더, 바디 데이터, 트레일러)
- 메시징 프로토콜 (gRPC, REST 등)
정교한 L7 로드밸런서는 위 하위계층들 각각에 관련된 기능들을 제공할 것이다. 어떤 L7 로드밸런서는 L7 카테고리 기능의 부분집합만 지원할 수도 있다. 요약하자면, 기능 비교 관점에서 L7 로드밸런서 환경은 L4 카테고리보다 훨씬 복잡하다. (이 문단은 HTTP에 대해서만 언급했지만, Redis, Kafka, MongoDB 등도 모두 L7 로드밸런싱을 활용하는 L7 어플리케이션 프로토콜이다.)
로드밸런서 기능
이 문단에서는 로드밸런서가 제공하는 고수준 기능을 간단히 요악할 것이다. 모든 로드밸런서가 이들 기능을 전부 제공하는 것은 아니다.
서비스 탐색(Service discovery)
서비스 탐색이란 로드밸런서가 가용한 백엔드 집합을 결정하는 처리 과정을 말한다. 구현 방법은 꽤 다양하며 다음 같은 예시가 있다:
- 정적 설정 파일.
- DNS.
- Zookeeper, Etcd, Consul, etc.
- Envoy’s universal data plane API.
상태 점검(Health checking)
상태 점검(Health checking)이란 로드밸런서가 백엔드가 트래픽 서비스 가능 여부를 판단하는 처리 과정을 말한다. 상태 점검은 일반적으로 두 가지로 분류된다:
- 능동적(Active): 로드밸런서가 백엔드로 정기적으로 핑을 보내 이를 사용해 상태를 측정한다. (이를테면, /healthcheck 엔드포인트로 HTTP 요청)
- 수동적(Passive): 로드밸런서는 기본 데이터 흐름으로 상태를 파악한다. 예를 들어, L4 로드밸런서는 커넥션 에러가 연달아 세번 일어나면 백엔드가 불량하다고 판단한다. L7 로드밸런서는 HTTP 응답 코드가 연달아 세번 503이면 백엔드가 불량하다고 판단한다.
부하분산(Load balancing)
그렇다, 로드밸런서는 실제로 부하를 분산해야 한다! 건강한 백엔드 집합이 주어졌을 때, 커넥션이나 요청을 서비스할 백엔드를 어떻게 선택하는가? 부하분산 알고리즘은 활발한 연구분야로, 임의선택/라운드로빈처럼 간단한 것부터 가변적인 지연시간이나 백엔드 부하를 고려하는 복잡한 알고리즘까지 다양하다. 성능/단순함을 고려했을 때 가장 널리 사용되는 부하분산 알고리즘 중 하나는 power of 2 least request load balancing으로 알려져있다.
고정 세션(Sticky sessions)
어떤 어플리케이션에서는 동일한 세션의 요청이 동일한 백엔드에 도달하는 것이 중요하다. 그 이유는 캐시, 임시 복합 구성 상태(temporary complex constructed state) 등일 수 있다. 세션의 정의는 다양하며 HTTP 쿠키, 클라이언트 커넥션 속성 혹은 또 다른 속성을 포함할 수 있다. 많은 L7 로드밸런서가 고정 세션을 지원한다. 한편, 세션을 호스팅하는 백엔드가 죽을 수 있기 때문에 세션고정은 본질적으로 취약성을 가지고 있다. 따라서 이에 의존하는 시스템을 설계할 때는 주의를 기울여야 한다.
TLS 종료(TLS termination)
TLS와, 엣지 서비스/서비스 간 통신 보안에서 TLS의 역할은 독자적인 게시물을 쓸만한 주제다. 그건 그렇다 치고, 많은 L7 로드밸런서가 종료, 인증서 검증 및 고정, SNI를 사용한 인증서 제공 등 많은 양의 TLS 처리를 수행한다.
관찰력(Observability)
내가 말하고 싶은 것은 "관찰력, 관찰력, 관찰력"이다. 네트워크는 본질적으로 신뢰할 수 없기 때문에 로드밸런서는 무엇이 잘못됐는지 통계, 자취(traces), 로그를 내보내 운영자가 문제를 해결하는 걸 돕는 역할을 종종 맡는다. 로드밸런서는 관찰 출력면에서 몹시 다양하다. 가장 진보한 로드밸런서는 수치 통계, 분산 추적(tracing), customizable 로깅을 제공한다. 물론 이런 강력한 관찰력이 공짜는 아니라서 로드밸런서가 추가적인 일을 수행해야 한다. 그러나, 데이터의 이점이 상대적으로 사소한 성능 손해보다 훨씬 크다.
보안 및 DoS 완화(Security and DoS mitigation)
특히 엣지 배포 토플로지에서, 로드밸런서는 종종 다양한 보안 기능을 구현한다. 이를 테면, 속도 제한, 인증, DoS 완화(IP주소 태깅 및 식별, 타피팅 등)등이 있다.
설정 및 제어부(Configuration and control plane)
로드밸런서는 설정이 필요하다. 거대 배포에서 이는 상당한 일이 될 수 있다. 일반적으로, 로드밸런서를 설정하는 시스템은 제어부(control plane)라고 부르며 구체적인 구현은 매우 다양하다. 이 주제에 대한 정보는 서비스 메시에 대한 다른 게시글, data plane vs. control plane을 참고하라.
그 외 많은 기능들
이 문단은 로드밸런서 기능 유형의 표면만 훑어본 것이다. 추가적인 논의는 후술할 L7 로드밸런서 문단에서 다룰 것이다.
로드밸런서 토플로지 유형
지금까지 다음 세 가지 주제를 다뤘다:로드밸런서의 고수준 개요, L4/L7 로드밸런서의 차이, 로드밸런서 기능의 요약. 이제 로드밸런서를 배포하는 다양한 분산 시스템 토플로지를 살펴보자. (다음 토플로지는 L4/L7 모두에 적용할 수 있다)
중간 프록시(Middle proxy)

그림 4: 중간 프록시 토플로지(Middle proxy load balancing topology)
그림4에서 보이는 중간 프록시 토폴로지가 대부분의 독자에게 가장 친숙한 로드 밸런싱 방식일 것이다. 이 카테고리는 HW 장치(Cisco, Juniper, F5 등)와 클라우드 SW 솔루션(아마존의 ALB/NLB, 구글 클라우드 로드밸런서), 순수 SW 자체 호스팅 솔루션(HAProxy, NGINX, and Envoy)을 모두 포괄한다. 중간 프록시 솔루션의 장점은 사용자 단순성이다. 일반적으로, 사용자는 DNS를 통해 로드밸런서에 연결하고 그밖에 다른 것에 대해서는 신경쓸 필요가 없다. 한편 단점은 프록시가 스케일링 병목이자 단일장애점이라는 사실이다.(클러스터된 경우조차도) 또 중간 프록시는 자주 블랙박스가 되어 운영을 어렵게 만든다. 문제가 클라이언트에 있는가? 물리 네트워크에 있는가? 중간 프록시에 있는가? 백엔드에 있는가? 구별하기 몹시 어려울 수 있다.
엣지 프록시(Edge proxy)

그림 5: 엣지 프록시 로드 밸런싱 토폴로지
그림 5의 엣지 프록시 토폴로지는 중간 프록시 토폴로지의 변형으로, 로드밸런서에 인터넷을 통해 접근할 수 있다는 부분만 다를 뿐이다. 이 시나리오에서 로드밸런서는 일반적으로 추가적인 "API 게이트웨이" 기능(TLS 종료, 속도 제한, 인증, 정교한 트래픽 라우팅 등)을 제공해야 한다. 엣지 프록시의 장단점은 중간 프록시와 동일하다. 주의할 점은 인터넷 지향 분산 시스템에서는 반드시 전용 엣지 프록시를 배포해야 한다는 점이다. 클라이언트는 일반적으로 서비스 주인이 제어하지 못하는 임의의 네트워크 라이브러리를 사용하는 DNS를 통해 시스템에 접근해야 한다. (다음절에서 설명할 임베디드 클라이언트 라이브러리나 사이드카 프록시 토폴로지를 클라이언트에서 직접 실행시킨다는 건 불가능하다) 추가적으로, 보안적인 이유로 모든 인터넷-대면 트래픽이 시스템으로 유입되는 게이트웨이는 단일인 것이 바람직하다.
임베디드 클라이언트 라이브러리(Embedded client library)

그림 6: 임베디드 클라이언트 라이브러리를 통한 로드 밸런싱
중간 프록시 토폴로지에 내재된 단일 장애점/스케일링 이슈를 해결하고자, 더 정교한 인프라는 로드밸런서를 직접 서비스에 라이브러리로 내장하는 형태로 진보했다.(그림6) 라이브러리는 지원하는 기능에 따라 매우 다양하지만, 이 카테고리에서 가장 잘 알려져있고 기능이 풍부한 것은 Finagle, Eureka/Ribbon/Hystrix, gRPC이다.(이중 gRPC는 내부 구글 시스템 Stubby에 느슨하게 의존하고 있다) 라이브러리 기반 솔루션의 주된 장점은 로드밸런서의 모든 기능을 완전히 각 클라이언트에게 분산시킨다는 것이다. 한편, 주된 단점은 라이브러리가 조직에서 사용하는 모든 언어로 구현되어야 한다는 사실이다. 분산 아키텍처는 점점 "다국어"가 되어가고 있다. 이런 환경에서, 극도로 정교한 네트워크 라이브러리를 여러 언어로 재구현하는 비용은 천문학적일 수 있다. 마지막으로, 대규모 서비스 아키텍처에서 라이브러리 업그레이드 배포는 쉽지 않으므로 프로덕션에서 파편화가 심해져 운영적/인지적 부하가 증가할 가능성이 높다.
그렇지만, 프로그래밍 언어 확장을 제한할 수 있고, 라이브러리 업그레이드 고통을 극복할 수 있는 회사들에게는 상술한 라이브러리가 성공적인 방법이었다.
사이드카 프록시(Sidecar proxy)
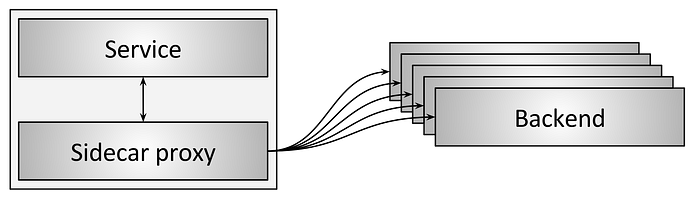
그림 7: 사이드카 프록시를 통한 로드밸런싱
그림7의 사이드카 프록시 토폴로지는 임베디드 클라이언트 라이브러리 로드밸런서 토폴로지의 변형이다. 최근 몇년간, 이 토폴로지는 "서비스 메시"로 대중화되었다. 사이드카 프록시의 근간 아이디어는, 다른 프로세스와 통신을 하는 과정에서 약간의 지연 페널티를 감수하기만 하면, 프로그래밍 언어를 제한하지 않고도 임베디드 라이브러리 접근법의 모든 이점을 얻을 수 있다는 것이다. 이 글을 쓰는 현재 가장 유명한 사이드카 프록시 로드밸런서는 Envoy, NGINX, HAProxy, Linkerd이다. 사이드카 접근법에 대한 상세한 정보는 다른 게시물 introducing Envoy와 service mesh data plane vs. control plane을 참고하라.
여러 로드밸런서 토폴로지의 장단점과 요약
- 중간 프록시 토폴로지는 일반적으로 사용하기 가장 쉬운 로드밸런싱 토폴로지다. 단점에는 단일장애점, 스케일링 한계, 블랙박스 동작이 된다는 것이 있다.
- 엣지 프록시 토폴로지는 미들 프록시와 유사하지만 일반적으로 항상 필요하다.
- 내장 클라이언트 라이브러리 토폴로지는 성능과 확장성이 가장좋지만, 라이브러리를 모든 언어로 개발해야한다는 문제 및 라이브러리 업그레이드를 모든 서비스에 배포해야한다는 문제가 있다.
- 사이드카 프록시 토폴로지는 임베디드 클라이언트 라이브러리 토폴로지보다는 성능이 떨어지지만, 모든 한계를 극복했다.
전반적으로, 필자는 사이드카 프록시 토폴로지(서비스 메쉬)가 점진적으로 서비스 간 통신에서 다른 모든 토폴로지를 대체할 것으로 예상한다. 엣지 프록시 토폴로지는 트래픽이 서비스 메쉬에 진입하기 전에 항상 필요하다.
L4 로드밸런싱에서 현재의 최선(state of the art)
L4 로드밸런서가 여전히 필요한가?(Are L4 load balancers still relevant?)
현대 프로토콜에서 L7 로드밸런서가 얼마나 훌륭한지는 이미 다루었고, L7 로드밸런서의 기능을 더 자세히 후술할 것이다. 그렇다면 L4 로드밸런서는 더이상 필요없다는 의미인가? 아니다! 내 의견으로는 서비스 간 통신에서는 L7 로드밸런서가 궁극적으로 L4 로드밸런서를 완전히 대체할 것이겠지만, L4 로드밸런서는 여전히 말단(edge)에서 극도로 유용하다. 거의 모든 현대의 대규모 분산 아키텍처가 인터넷 트래픽에 대해 이중 L4/L7 로드 밸런싱 아키텍처를 사용하고 있기 때문이다. 말단(edge) 배포에서 L7 로드밸런서 앞단에 전용 L4 로드밸런서를 배치하는 것의 이점은 다음과 같다:
- L7 로드밸런서는 어플리케이션 트래픽에 상당히 정교한 분석, 변형, 라우팅을 수행하기 때문에, 최적화된 L4 로드밸런서에 비하면 다룰 수 있는 트래픽 부하가 비교적 적다. (초당 처리 패킷수/바이트수 기준) 이 때문에 일반적으로 L4 로드밸런서가 특정 유형의 DoS 공격을 처리하기 더 적절하다. (예: SYN fllods, generic packet flood 공격 등)
- L7 로드밸런서는 L4 로드밸런서보다 개발이 활발하고, 배포가 빈번하고, 버그가 많은 경향이 있다. L7 로드밸런서 배포중에 헬스체킹과 드레이닝이 가능한 L4 로드밸런서를 앞단에 배치하는 것이 BGP와 ECMP를 사용하는 현대 L4 로드밸런서와 사용하는 배포 메커니즘보다 훨씬 쉽다. (자세한 것은 후술) 마지막으로, L7 로드밸런서는 기능이 복잡해서 버그가 있을 가능성이 높기 때문에, 장애/이상징후를 우회할 수 있는 L4 로드밸런서를 두면 시스템 전반의 안정성을 높일 수 있다.
다음 문단에서는 미들/엣지 프록시 L4 로드밸런서를 위한 몇가지 설계를 설명할 것이다. 다음 설계들은 클라이언트 라이브러리와 사이드카 프록시 토폴로지에는 일반적으로 적용할 수 없다.
TCP/UDP termination load balancers
그림 8: L4 termination 로드밸런서
여전히 사용중인 L4 로드밸런서의 첫번째 유형은 종료 로드밸런서다.(그림 8) 이는 위에서 L4 로드밸런싱 소개에서 봤던 것과 동일한 로드밸런서다. 이 유형에서는 두 개의 개별 TCP 커넥션을 사용한다: 하나는 클라이언트-로드밸런서이고, 하나는 로드밸런서-백엔드이다.
L4 종료 로드밸런서는 두 가지 이유에서 여전히 사용중이다:
- 구현이 상대적으로 쉽다.
- 클라이언트에 근접한(low latency) 커넥션 종료는 성능에 상당한 영향을 준다. 특히, terminating 로드밸런서가 손실 네트워크(cellular 등)를 사용하는 클라이언트 가까이에 배치될 수 있는 경우, 데이터가 신뢰할 수 있는 섬유 통신에 옮겨지기도 전에 재전송이 발생할 수 있다. 달리 말하면, 이 유형의 로드밸런서는 raw TCP 연결 종료를 위한 POP(Point of Presence, 인터넷 접속 거점)으로 사용할 수 있다.
TCP/UDP passthrough 로드밸런서
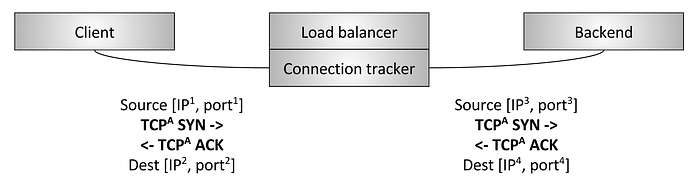
그림 9: L4 passthrough 로드밸런서
L4 로드밸런서 두 번째 유형은 passthrough 로드밸런서이다.(그림9) 이 유형에서, TCP 연결은 로드밸런서가 종료하지 않는다. 대신에, 연결 추적 및 NAT(Network Address Translation)가 일어난 후 각 연결에 대한 패킷이 선택된 백엔드로 전달(forward)된다. 먼저, 연결 추적과 NAT를 정의해보자:
- 연결 추적(Connection tracking): 활성화된 모든 TCP 연결 상태를 추적하는 프로세스다. 포함하는 정보에는 핸드쉐이크 마무리 여부, FIN 수신 여부, 커넥션 아이들 지속 시간, 연결에 선택된 백엔드 등이 있다.
- NAT: NAT는 커넥션 추적 데이터를 사용해 패킷이 로드밸런서를 통과할 때 IP/port 정보를 변조하는 프로세스다.
연결 추적과 NAT를 사용해, 로드밸런서는 클라이언트에서 백엔드로 대부분의 raw TCP 트래픽을 통과시킬 수 있다. 예를 들어, 클라이언트가 1.2.3.4:80와 통신중이고, 선택된 백엔드는 10.0.0.2:9000에 있다고 해보자. 클라이언트 TCP 패킷은 1.2.3.4:80에 있는 로드밸런서에 도착할 것이다. 로드밸런서는 패킷의 목표IP와 포트를 10.0.0.2:9000으로 변조할 것이다. 또한 패킷의 소스IP와 포트도 로드밸런서의 것으로 변조할 것이다. 그러므로, 백엔드가 TCP 연결에 응답할 때는, 패킷은 연결 추적이 동작중인 로드밸런서로 돌아가게 되어 NAT가 역방향으로 일어날 수 있다.
passthrough 로드밸런서가 이전 문단에서 설명한 종료 로드밸런서보다 더 복잡한데도 대신 사용하는 이유가 무엇인가? 몇 가지 이유가 있다:
- 성능 및 자원활용: passthrough 로드밸런서는 TCP 연결을 종료하지 않기 때문에, TCP 연결 윈도우를 버퍼링할 필요가 없다. 연결당 상태 저장량은 매우 적고, 일반적으로 효율적인 해시 테이블 조회로 접근한다. 이 때문에, passthrough 로드밸런서는 일반적으로 terminating 로드밸런서보다 상당히 많은 수의 활성 연결과 초당 패킷(PPS)을 다룰 수 있다.
- 백엔드가
혼잡 제어(congestion control)가능: TCP 혼잡제어는 사용가능한 대역폭 및 버퍼를 초과하지 않도록 인터넷의 엔드포인트가 데이터 전송을 제한하는 메커니즘이다. passthrough 로드밸런서는 TCP 연결을 종료시키지 않기 때문에, 혼잡 제어에 참가하지 않는다. 덕분에 백엔드는 어플리케이션에 따라 다른 혼잡제어 알고리즘을 사용할 수 있다. 또한 혼잡 제어 변경에 대한 실험도 더 쉬워진다.(예: 최근의 BBR rollout) - DSR(직접 서버 반환, Direct Server Return)의 토대 형성: Passthrough 로드밸런싱은 더 진보한 L4 로드밸런싱 기술에 필수적이다.(DSR, 분산 consistent 해싱에서 클러스터링 등, 자세한 것은 이후 문단에서 다룰 것이다)
Direct server return (DSR)

그림 10: L4 Direct server return (DSR)
그림 10에 나타나 있는 것이 Direct Server Return (DSR) 로드밸런서이다. DSR은 이전 문단에서 설명한 passthrough 로드밸런서를 기반으로 하고 있다. DSR이란 수신/요청 패킷만 로드밸런서를 통과하는 최적화 형태를 의미한다. 송신/응답 패킷은 로드밸런서를 우회하고 클라이언트에게 바로 향한다. DSR이 흥미로운 이유는 많은 워크로드에서 응답 트래픽이 요청 트래픽보다 훨씬 많기 때문이다.(예: 일반적인 HTTP 요청/응답 패턴) 트래픽 중 10%가 요청 트래픽이고 90%가 응답 트래픽이라고 가정하면, DSR을 사용했을 때는 로드밸런서의 사양이 종전의 1할만으로도 시스템의 필요성을 만족시킬 수 있다. 역사적으로 로드밸런서는 극히 비쌌기 때문에, 이 유형의 최적화는 시스템 비용과 신뢰성에 상당한 영향을 줄 수 있다.(저렴해서 나쁠 건 없잖은가) DSR 로드밸런서는 passthrough 로드밸런서의 개념을 다음과 같이 확장한다:
- 로드밸런서는 일반적으로 커넥션 추적을 부분적으로 수행한다. 응답 패킷이 로드밸런서를 통과하지 않기 때문에, 로드밸런서는 TCP 커넥션 상태를 온전히는 알 수 없다. 그러나, 로드밸런서는 여러 유형의 아이들 타임아웃을 사용하고 클라이언트 패킷을 봄으로써 상태를 강하게 추론할 수 있다.
- NAT 대신, 로드밸런서는 일반적으로 로드밸런서에서 백엔드로 보내지는 GRE(Generic Routing Encapsulation)를 사용해 로드밸런서에서 백엔드로 전송된 IP 패킷을 캡슐화한다. 그러므로, 백엔드가 캡슐화된 패킷을 수신했을 때 이를 decapsulate해 클라이언트의 본래 IP와 TCP 포트를 알 수 있다. 이를 통해 응답 패킷이 로드밸런서를 거치지 않고도 백엔드가 클라이언트로 직접 응답할 수 있다.
- DSR 로드밸런서의 중요한 부분은 백엔드가 로드밸런싱에 직접 참여한다는 점이다. 백엔드는 적절히 설정된 GRE 터널이 필요하고, 네트워크의 로우레벨 설정에 따라서는 자체 커넥션 추적, NAT 등이 필요할 수도 있다.
passthrough/DSR 로드밸런서 구조(design) 모두에서, 로드밸런서와 백엔드에서 커넥션 추적, NAT, GRE등을 설정할 수 있는 방법은 몹시 다양함을 주의하라. 안타깝지만 해당 주제는 이 게시물의 범위를 넘어서는 것이다.
고가용성 쌍을 통한 내결함성(Fault tolerance via high availability pairs)

그림 11: HA 쌍과 커넥션 추적을 통한 L4 내결함성
지금까지, 우리는 L4 로드밸런서 설계만을 단독으로 고려해왔다. passthrough와 DSR 로드밸런서 모두 로드밸런서 그 자체애 커넥션 추적과 상태가 일정량 필요하다. 로드밸런서가 죽으면 어떻게 되는가? 로드밸런서 단일 인스턴스가 죽으면, 해당 로드밸런서를 경유하던 모든 커넥션이 끊어진다. 어플리케이션에 따라, 이것이 어플리케이션 성능에 중대한 영향을 줄 수도 있다,
역사적으로, L4 로드밸런서는 특정 벤더에서 구매한 HW 장비들이었다.(시스코, 주니퍼, F5등.) 이 장치들은 극히 비싸고 많은 양의 트래픽을 다뤘다. 단일 로드밸런서 장애가 모든 커넥션을 끊어 상당한 어플리케이션 작동 중단으로 이어지는 걸 피하고자, 로드밸런서는 일반적으로 고가용쌍으로 배포되어왔다.(그림 11) 일반적인 고가용 로드밸런서 설정은 다음과 같이 설계되었다:
- 고가용 엣지 라우터 쌍 하나는 여러 가상IP(VIP)를 서비스한다. 이들 엣지 라우터는 BGP(Border Gateway 프로토콜)을 사용해 VIP를 공지한다. 프라이머리 엣지 라우터는 백업보다 BGP 가중치가 높기 때문에, 안정적인 상태에서는 모든 트래픽을 처리한다. (BGP는 극도로 복잡한 프로토콜이다; 이 게시물에서는 목적상 BGP를 두 가지 메커니즘으로만 고려할 것이다. 1. 네트워크 장치가 다른 장치로부터 트래픽을 받아 처리할 수 있음을 고지하는 메커니즘 2. 각 링크는 링크 트래픽에서 우선순위를 결정하는 가중치를 부여받을 수 있다.)
- 마찬가지로, 프라이머리 L4 로드밸런서도 자신을 백업보다 BGP 가중치가 높은 엣지 라우터로 공지하므로, 안정적인 상태에서는 모든 트래픽을 처리한다.
- 프라이머리 로드밸런서는 백업에 교차연결되고, 모든 커넥션 추적 상태를 공유한다. 그러므로 프라이머리가 죽으면, 백업이 모든 활성 커넥션을 도맡아 처리할 수 있다.
- 두 엣지 라우터와 두 로드밸런서는 모두 교차연결된다. 즉, 엣지라우터나 로드밸런서 중 하나가 죽을 경우나, BGP 공지가 어떤 이유로 취소될 경우, 백업이 모든 트래픽을 처리할 수 있다.
상술한 설정은 오늘날 인터넷 어플리케이션이 얼마나 트래픽을 많이 처리하는지를 보여주는 것이다. 그러나, 위 접근방식에는 상당한 단점이 있다:
- VIP는 반드시 용량 사용을 고려하여 HA 로드밸런서 쌍들에 적절히 분배되어야 한다. 만약 단일 VIP가 단일 HA쌍의 수용량을 넘어설 경우, VIP는 복수의 VIP로 분할되어야 한다.
- 시스템의 자원 활용이 형편없다. 안정된 상태에서 수용능력의 50%는 유휴 상태에 머무른다. 역사적으로 HW 로드밸런서가 극도로 비쌌음을 고려한다면, 이는 곧 상당한 양의 유휴자본을 의미하는 것이다.
- 현대 분산시스템 설계는 활성/백업이 제공하는 것보다 큰 내결함성을 선호한다. 예를 들어, 이상적으로는 시스템이 복수의 동시 장애에도 계속 동작할 수 있어야한다. active/backup 로드밸런서가 동시에 사망할 경우 HA 로드밸런서 쌍은 전체 장애(total failure)에 취약하다.
- 벤더의 독점 대형 HW 장치는 몹시 비싸고 벤더에 종속되게 만든다. 그러므로 이를 범용 컴퓨팅 서버를 사용해 구축한, 수평적으로 확장가능한 SW 솔루션으로 대체하는 것이 바람직하다.
분산 consistent 해싱 클러스터를 통한 내결함성과 스케일링

그림 12: 분산 consistent 해싱 클러스터를 통한 L4 내결함성과 스케일링
이전 문단에서는 HA쌍을 통한 L4 로드밸런서 내결함성과 그 설계에 내재된 문제를 소개했다. 2000년대 초반부터 중반까지 대규모 인터넷 인프라는 새로운 대규모 병렬 L4 로드 밸런싱 시스템을 설계하고 배포하기 시작했다.(그림 12) 이 시스템의 목적은 다음과 같다:
- 이전 문단에서 설명한 HA쌍 설게의 모든 단점을 완화한다.
- 벤더의 독점 HW 로드밸런서에서 벗어나 범용 컴퓨터 서버와 NIC을 사용해 구축한 상용 SW 솔루션으로 이동한다.
이 L4 로드밸런서 설계는 클러스터링과 분산 일관 해싱을 통한 내결함성과 스케일링으로 가장 잘 알려져있다. 이는 다음 방식으로 동작한다:
- N 개의 엣지 라우터가 모든 애니캐스트 VIP를 동일한 BGP 가중치로 공지한다. 일반적으로 단일 흐름의 모든 패킷이 동일한 엣지 라우터로 도달하도록 보장하기 위해 동일비용 복수경로 라우팅(ECMP, Equal-cost multi-path)을 사용한다. 흐름은 일반적으로 소스 IP/포트와 목표 IP/포트의 4-튜플이다. (즉, ECMP는 동일 가중치 네트워크 링크 집합에서 동일 해싱을 사용해 패킷을 분배하는 방법이다) 엣지 라우터 그 자체는 어느 패킷이 어디에 도착할지를 특별히 고려하지는 않지만, 일반적으로 한 흐름의 모든 패킷은 동일 링크 집합을 통과하는 것이 좋다. 성능 저하를 유발하는 패킷 순서 뒤섞임을 방지할 수 있기 때문이다.
- N개의 L4 로드밸런서 머신들은 엣지 라우터들에게 모든 VIP를 동일 가중치로 공지한다. 다시 ECMP를 사용해, 엣지 라우터들은 일반적으로 한 흐름에는 동일한 로드밸런서를 선택한다.
- 각 L4 로드밸런서 머신은 일반적으로 부분 커넥션 추적을 수행하고, 일관 해싱을 사용해 흐름의 백엔드를 선택한다. GRE는 로드밸런서에서 백엔드로 보낸 패킷을 encapsulate할 때 사용한다.
- 그리고나서 DSR을 사용해 백엔드에서 엣지 라우터를 경유해 바로 클라이언트로 패킷을 보낸다.
- L4 로드밸런서가 사용하는 실제 일관 해싱 알고리즘은 활발한 연구분야다. 일반적으로 다음 중요지표 간에는 상충관계(trade-off)가 있다:
- 부하 균등화
- 지연시간 최소화
- 백엔드 변경 중 중단 최소화
- 메모리 오버헤드 최소화
이 주제에 대한 완벽한 논의는 이 게시글의 주제를 벗어나는 것이다.
이제 상술한 디자인이 어떻게 HA쌍 접근법의 모든 단점을 완화하는지 살펴보자:
- 새 엣지 라우터와 로드밸런서 머신은 필요한만큼 추가할 수 있다. 모든 계층에서 일관된 해싱을 사용해 새 머신이 추가될 때마다 영향받는 플로우의 갯수를 가능한 줄인다.
- 시스템의 자원 활용은 내결함성과 충분한 버스트 여유분을 유지하면서 원하는 만큼 높게 동작할 수 있다.
- 현재는 엣지 라우터와 로드밸런서 모두 범용 HW를 사용해 전용 HW 로드밸런서 비용의 극히 일부만으로 구축할 수 있다. (자세한 것은 후술)
이 설계에 대해 흔히 하는 질문 하나는 "왜 엣지 라우터가 ECMP를 통해 백엔드에 직접 통신하지 않는가? 왜 로드밸런서가 필요한 것인가"라는 것이다. 그 이유는 주로 DoS 완화와 백엔드 운영 용이성에 있다. 로드밸런가 없다면, 각 백엔드는 BGP에 참가해야 하고, rolling 배포를 수행하는 상당히 힘든 시간을 보내야 한다.
모든 현대 L4 로드밸런싱 시스템은 이 디자인(혹은 그 변종)으로 이동하고 있다. 가장 잘 알려진 사례 두 가지는 구글의 Maglev와 아마존의 NLB다. 현재는 이 설계를 구현한 OSS 로드밸런서가 없지만, 2018년에 OSS에 릴리즈 계획중인 회사는 있다. 현대적인 L4 로드밸런서가 네트워크 공간에서 잃어버린 OSS의 중요한 조각이기 때문에 이 릴리즈가 개인적으로 몹시 흥분된다.
L7 로드밸런싱의 현재 최첨단
현재 기술계의 프록시 전쟁은 말 그대로 대리전이다.
혹은 "대리인들의 전쟁"이든가.Nginx plus,HAProxy,linkerd,Envoy모두 말 그대로 죽인다.
그리고 프록시aaS/라우팅aaS SaaS 벤더들도 기준을 높이고 있다. 몹시 흥미로운 시간이다!
정말로, 그렇다. 지난 몇년간 L7 로드밸런서/프록시 개발이 부활했다. 이는 분산시스템의 마이크로서비스 아키텍처로의 지속적인 추진과 잘 맞닿아있다. 기본적으로, 본질적으로 결함있는 네트워크는 빈번하게 사용할 때 효율적으로 운영하기가 훨씬 어려워진다. 게다가, 오토스케일링, 컨테이너 스케줄러 등의 부상은 정적 파일로 정적IP를 프로비전하던 시대가 이미 지나갔음을 의미한다. 시스템들은 네트워크를 더 잘 활용할 뿐만 아니라, 훨씬 더 동적이어서 로드밸런서에 새 기능을 요구하고 있다. 이 문단에서 나는 현대 L7 로드밸런서에서 가장 많이 개발되고 있는 영역을 간단하게 요약할 것이다.
프로토콜 지원
최신 L7 로드밸런서는 여러 프로토콜 지원을 명시적으로 더하고 있다. 로드밸런서가 어플리케이션 트래픽에 대해 더 많이 알수록 할 수 있는 것들이 훨씬 정교해진다. (관찰 결과물, 진보된 로드밸런싱/라우팅 등) 예를 들어, 이 글을 쓰는 시점에서는 Envoy가 HTTP/1, HTTP2, gRPC, Redis, MongoDB, DynamoDB 등에 대해 명시적으로 L7 프로토콜 파싱/라우팅을 지원하고 있다. 추후에는 MySQL, Kafka 등 더 많은 프로토콜이 추가될 것이다.
동적 설정(Dynamic configuration)
상술했듯, 분산 시스템의 동적 특성이 증가함에 따라 동적,반응형 제어 시스템을 만드는 데 병렬 투자가 필요해지고 있다. Istio가 그런 시스템 중 하나다. 이 주제에 대한 자세한 정보는 다른 게시글 service mesh data plane vs. control plane을 참고하라.
진보한 부하분산(Advanced load balancing)
L7 로드밸런서는 이제 흔히들 진보한 부하분산 기능을 내장하고 있다. 이를 테면 timeouts, 재시도, 속도제한, 회로차단(circuit breaking), shadowing, 버퍼링, 컨텐츠 기반 라우팅 등.
관찰력(Observability)
로드밸런서 일반 기능 문단에서 설명한 것처럼, 점점 더 동적이 되고 있는 시스템은 점점 디버깅하기 어려워지고 있다. 강력한 프로토콜 특정 관찰 출력은 아마 현대 L7 로드밸런서의 가장 중요한 기능일 것이다. L7 부하분산 솔루션에는 수치 통계, 분산 추적, 커스터마이징한 로깅 출력이 사실상 필수적이다.
확장가능성(Extensibility)
최신 L7 로드밸런서 사용자들은 종종 커스텀 기능을 추가해 쉽게 확장하고 싶어한다. 이는 로드밸런서에 로드되는 pluggable 필터를 써서 가능하다. 많은 로드밸런서들도 스크립팅을 지원하고 있는데, 일반적으로 Lua를 사용한다.
내결함성(Fault tolerance)
앞서 L4 로드밸런서 내결함성에 대해 꽤 자세히 설명했다. L7 로드밸런서의 내결함성은 어떤가? 일반적으로, L7 로드밸런서를 소모성 및 무상태로 취급한다. 상업용 SW를 사용하면 L7 로드밸런서를 쉽게 수평적으로 확장할 수 있다. 게다가, L7 로드밸런서가 수행하는 처리작업 및 상태추적은 L4보다 상당히 복잡하다. L7 로드밸런서의 HA쌍을 만들고자 하는 시도는 기술적으로는 가능하지만 힘든 일이 될 것이다.
전반적으로, L4와 L7 로드밸런싱 영역에서, 대세는 HA 쌍에서 일관된 해싱을 통해 수렴하는 수평적 확장가능 시스템으로 이동하고 있다.
그리고 더
L7 로드밸런서는 엄청난 속도로 진화하고 있다. 예를 들어, Envoy가 제공하는 것을 보려면 Envoy의 아키텍처 개요를 살펴보라.
글로벌 부하분산 및 중앙화된 컨트롤 플레인(Global load balancing and the centralized control plane)
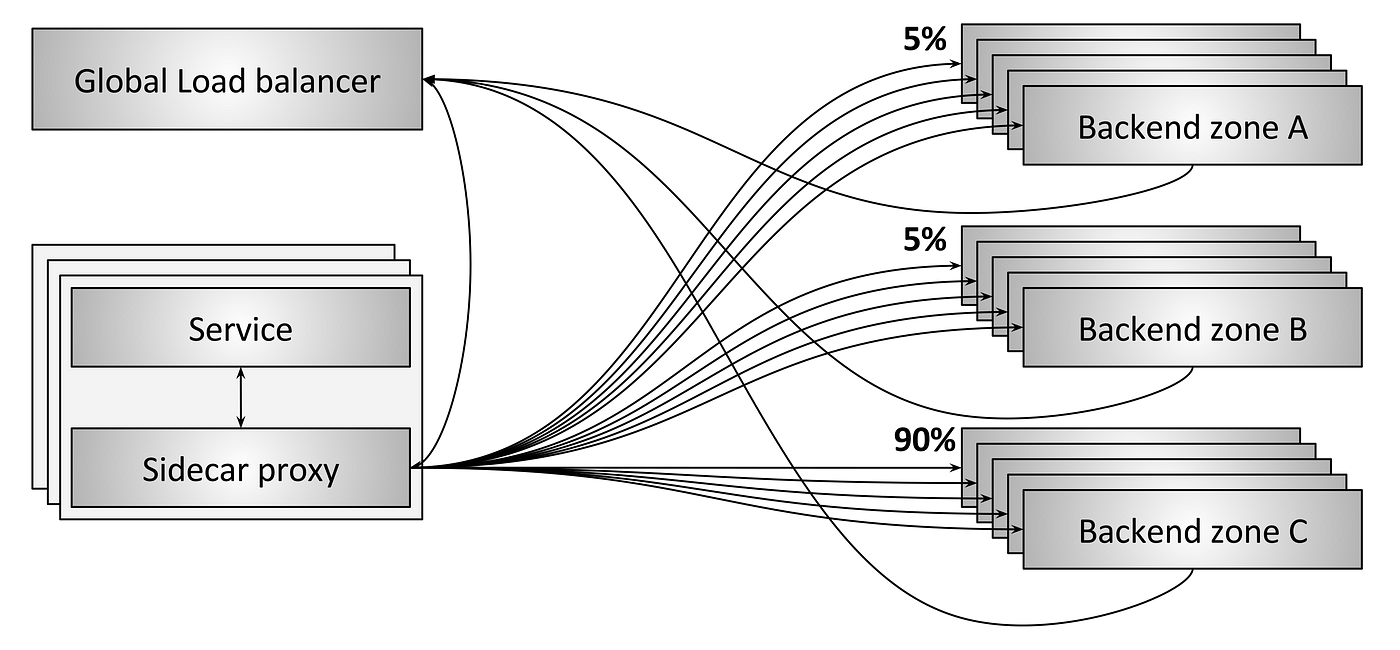
그림 13: 전역 부하분산
부하분산의 미래는 개별 부하분산 장치를 일반 장치로 취급하는 것일 것이다. 개인적인 생각으로는, 진정한 혁신과 상업적 기회는 모두 제어영역에 있을 것이다. 그림 13은 전역 부하분산 시스템을 보여준다. 이 예제에서, 다음과 같은 몇 가지 다른 일들이 일어나고 있다:
- 각 사이드카 프록시는 서로다른 세 영역(A,B,C)에 있는 백엔드와 통신하고 있다.
- 그림과 같이, A와 B로는 트래픽의 5%만 가고 있는 반면, C로는 트래픽의 90%가 가고 있다.
- 사이드카 프록시와 백엔드는 모두 전역 로드밸런서에게 주기적(periodice) 상태를 보고하는 중이다. 덕분에 전역 로드밸런서는 지연시간, 비용, 부하, 현재 장애 등을 고려한 결정을 내릴 수 있다.
- 전역 로드밸런서는 주기적으로 각 사이드카 프록시를 현재 라우팅 정보로 설정할 수 있다.
전역 로드밸런서는 점차 개별 로드밸런서 수준에서는 할 수 없는 정교한 일을 할 수 있게 될 것이다. 이를 테면:
- 존 장애를 자동으로 감지,우회할 수 있다.
- 전역 보안,라우팅 규칙을 적용할 수 있다.
- 기계학습과 인공신경망을 활용해 DDoS 공격 등 트래픽 이상을 감지,완화할 수 있다.
- 엔지니어가 분산시스템 전체를 이해하고 운영할 수 있도록 중앙화된 UI/시각화 기능을 제공한다.
글로벌 부하분산이 가능하려면, 데이터 플레인으로 사용하는 로드밸런서에 정교한 동적 설정 기능이 있어야한다. 이 주제에 대한 상세한 정보는 다른 게시글 service mesh data plane vs. control plane과 Envoy’s universal data plane API을 참고하라.
HW에서 SW로의 진화
지금까지 이 개시글은 주로 역사적 L4 로드밸런서 HA쌍의 맥락에서 HW vs SW를 간단하게만 언급해왔다. 이 영역의 대세는 무엇인가?
SW 레이어 8개로 이루어진 새 OSI 스택을 보았다. 내 생각엔 그건 좀 더 여기에 가까운 것 같아:

위 트윗은 우스갯소리지만 트렌드를 꽤 잘 함축하고 있는 것이다:
- 역사적으로, 라우터와 로드밸런서는 극히 비싼 전용 HW로 제공되어왔다.
- 점차, 전용 L3/L4 네트워크 장비들은 상용 서버 HW, 상용 NIC, 특화된 SW 솔루션(IPVS, DPDK, fd.io같은 프레임워크에 기반)으로 대체되어 가고 있다. 가격이 $5K 미만인 현대 데이터 센터 머신도 80Gbps NIC을 DPDK를 사용해 작성한 커스텀 사용자-공간 어플리케이션과 리눅스만을 사용해 쉽게 포화시킬 수 있다. 한편, 놀라운 집계(aggregate) 대역폭과 패킷 속도로 ECMP 라우팅을 할 수 있는 저렴한 기본 라우터/스위치 ASIC는 범용 라우터로 포장되고 있다.
- NGINX, HAProxy, Envoy 등 정교한 L7 SW 로드밸런서도 F5 같은 벤더의 영역이었던 것을 빠르게 잠식하고 있다.
- 동시에, IaaS, CaaS, FaaS로의 전환 추세는 엔지니어 중 극히 일부만이 실제 물리 네트워크의 동작을 이해하면 된다는 것을 의미한다.(이들이 바로 "흑마술"이자 "우리가 더 이상 알 필요없는 것들"이다.)
결론 및 부하분산의 미래
요약하자면, 이 게시글의 핵심은 이렇다:
- 로드밸런서는 현대 분산 시스템의 핵심 구성요소다.
- 로드밸런서에는 크게 두 종류가 있다: L4/L7
- L4/L7 로드밸런서 모두 현대 아키텍처에서 필요하다.
- L4 로드밸런서는 수평적 확장가능한 분산 일관성(distributed consistent) 해싱 솔루션으로 이동하고 있다.
- L7 로드밸런서는 동적 마이크로서비스 아키텍처의 확산으로 인해 많은 투자를 받고 있다.
control plane과data plane의 분할과 전역 부하분산은 부하분산의 미래이며, 여기에 미래혁신과 경제적 기회가 있을 것이다.- 업계는 네트워크 솔루션을 상업용 OSS HW/SW로 공격적으로 이동하고 있다. F5같은 전통 로드밸런싱 벤더들이 제일 먼저 OSS SW와 클라우드 벤더로 대체될 것이라 믿는다. 전통 라우터/스위치 벤더들(Arista/Cumulus 등)은 온프레미스 배포 덕분에 사정이 좀 낫긴 하겠지만 궁극적으로는 역시 퍼블릭 클라우드 벤더와 자신들의 물리 네트워크로 대체될 것이다.
종합적으로, 지금이 컴퓨터 네트워크에서 흥미로운 시기라고 생각한다! 대부분의 시스템이 OSS와 SW로 바뀌면서 반복 속도가 수십배로 증가하고 있다. 게다가, 분산시스템이 "서버리스" 패러다임을 통해 계속해서 역동성을 추구하고 있으므로, 기반 네트워크와 로드밸런싱 시스템의 정교함도 그에 상응하여 증가할 필요성이 생길 것이다.
===
본 게시글은 다음 글을 번역한 것입니다. 문제가 있다면 삭제하도록 하겠습니다.
출처: Introduction to modern network load balancing and proxying